Nibble. A treewalk interpreter for expressions.
So, this is hopefully the first post in what I would like to be an ongoin series I'm going to call "Monthly Deep Dives"! Where each month I'll allocate some time to digging into something, with the goal being to learn more and come out the other side with a technical artifact of some sort. This month (June), I chose to focus on programming languages and their implementation. Continue reading if you want to hear more about formal grammars, lexical analysis, parsing, and more!
For the sake of brevity I'm not going to include much code in this post, but you can find it all on GitHub if you want to follow along 🙂
Motivation
I'll start by addressing why I wanted to explore this area of software in the first place. My first programming language was Java, and I've since coded in probably a dozen other languages if you include things like markup and DSL's. However, I've never really dug into the internals of a language before. Relying on the abstractions the languages provide is pretty standard practice, and it's something that I'll of course continue to do. However, I find understanding how and why those abstractions work to be rewarding.
I think that understanding this part of the software stack can help you appreciate the design choices between languages and maybe better evaluate which language is best suited to your projects, and more generally if you understand language design and implementation then I think you will be better able to learn new languages as necessary because ultimately you understand that there are no magical encatations that make languages work, only design decisions made by other engineers.
A very rich area of software engineering
If you think about it, programming languages are the ultimate developer tool. Without them we would all be writing code in 0's and 1's, which would basically make writing the types of software we all know and love be impossible, or at the very least excruciatingly slow.
So, then it makes sense for this area of software to have a lot of depth, and boy does it! The following are some of the larger areas I had to learn about in building this, but rest assured there are many, many more areas that I did not cover at all.
- Formal Grammars
- Chomsky Hierarchy
- Backus-Naur Form
- Lexical Analysis
- Parsing
- Abstract Syntax Trees (AST's)
10,000 foot view: Theory
We basically follow laws derived from formal grammars and Chomsky's hierarchy when designing languages. A common part of designing a language is formalizing the grammar, and this is typically done in Backus-Naur Form. For Nibble that looks like this:
program ::= expression EOF ;
expression ::= term ;
term ::= factor ( ("+" | "-") factor )* ;
factor ::= primary ( ("*" | "/") primary )* ;
primary ::= NUMBER
| "(" expression ")" ;
If like me a few weeks ago, you think that looks very strange have no fear, all it means is this:
expression handles the lowest-precedence level
term handles + and -
factor handles * and /
primary handles numbers and parenthesized expressions
This is very small compared to modern programming language grammars, but it is enough to get you started.
10,000 foot view: Implementation
Alright, so with the theory out of the way let's now dive into the implementation. The implementation comes in three key stages:
- Lexing -- taking raw source code text and transforming it into tokens.
- Parsing -- taking those tokens and parsing them into an AST according to our languages grammar.
- Treewalk Interpretation -- recursively traverse the AST and evaluate each node to produce a result.
That's pretty much it!......... Well, from 10k feet anyways.
Recursive Descent Parsing: the beauty that ties it all together
Maybe the most beautiful part of the project is the clear mapping from grammar to implementation. Check this out:
expression(Parser* parser);
term(Parser* parser);
factor(Parser* parser);
primary(Parser* parser);
If you look back at our formal grammar definition you will see that these C functions map directly to it. Essentially, creating a recursive structure that makes the implementation relatively straighforward to reason about.
Here is a diagram of the architecture that may clear up the flow of data. 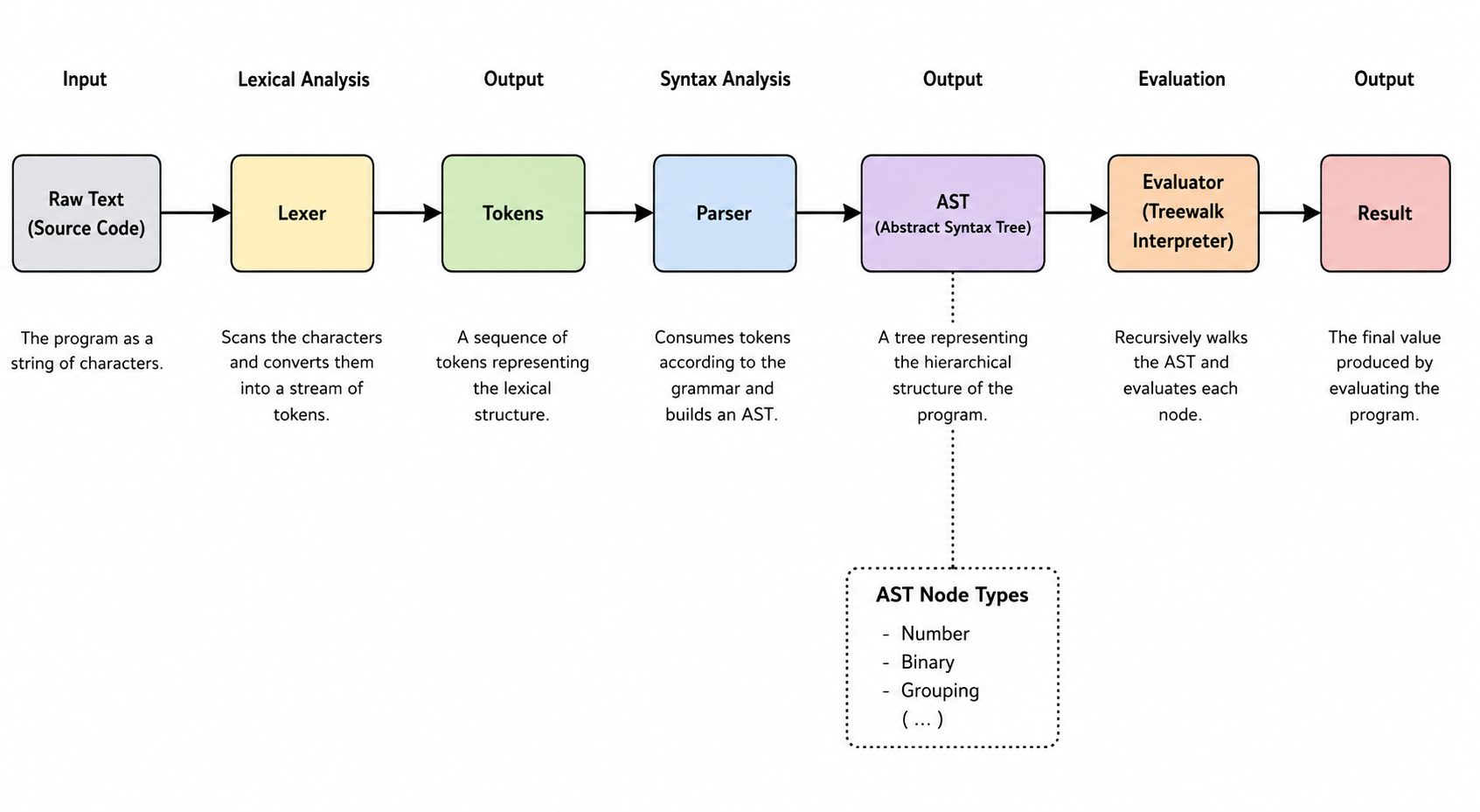
Learning and Critiques from this project
Learnings
I learned a ton from this, most of what I wrote about above was completely new to me less than a month ago. Of course, there is much more uncharted territory that I didn't make it to like: Semantic Analysis, Type Theory, Compiling to Bytecode, and things like that.....that'll be for another time and another post.
I would say something unexpected that I observed was the natural veering of my implementation toward object oriented style programming (OOP). Notably, C is not an OOP style language but even so with the usage of tagged unions and the like it is easy to see why language designers eventually gravitated towards just building classes into their programming languages.
Another thing I really appreciated was just the organization of the code, for a project like this with so many boundaries (lexing, parsing, evaluating, etc.) you really had to keep it modular and make sure that the components played nicely together in order for it to work as desired. I think this is true of just about any reasonably complex system.
Critiques
This project was not what I had originally planned to build, but as I got going on it I realized a lot of the implementation was more grunt work than learning new concepts so I dialed back the scope to keep it finishable in a reasonable amount of time. I had originally planned to implement a C like language if you were curious.
I would probably recommend someone looking to dive into this area of software to look at some basic implementations of languages with easier/smaller syntax. (think BASIC, Scheme, etc.). Also, unless you, like me, have a specific affinity for seeing "how the sausage gets made" you may be better off writing your project in a higher-level language like Python, Java, etc. not because C isn't perfectly capable, it's just more work since the higher-level languages provide more abstractions around memory management, I/O, etc.
I have not went through these myself but I've heard good things if you're interested in going this route: How to write a lisp interpreter in Python, Let's make a Teeny Tiny compiler.
I used Crafting Interpreters, a great free resource by Bob Nystrom, to learn some basics. I found myself quickly looking for additional resources because I wanted a lower-level view of what was being built than the Java implementation Bob built in the book. I didn't really find one. If you are looking for something similiar then reading through my code may be a good first step. Although it is far from as complete as what Bob implemented.
Cheers!
until next time,
Denver